Ship 2.0
We just released Ship 2.0, a fast and comprehensive macOS native interface to GitHub Issues. You can download it here.
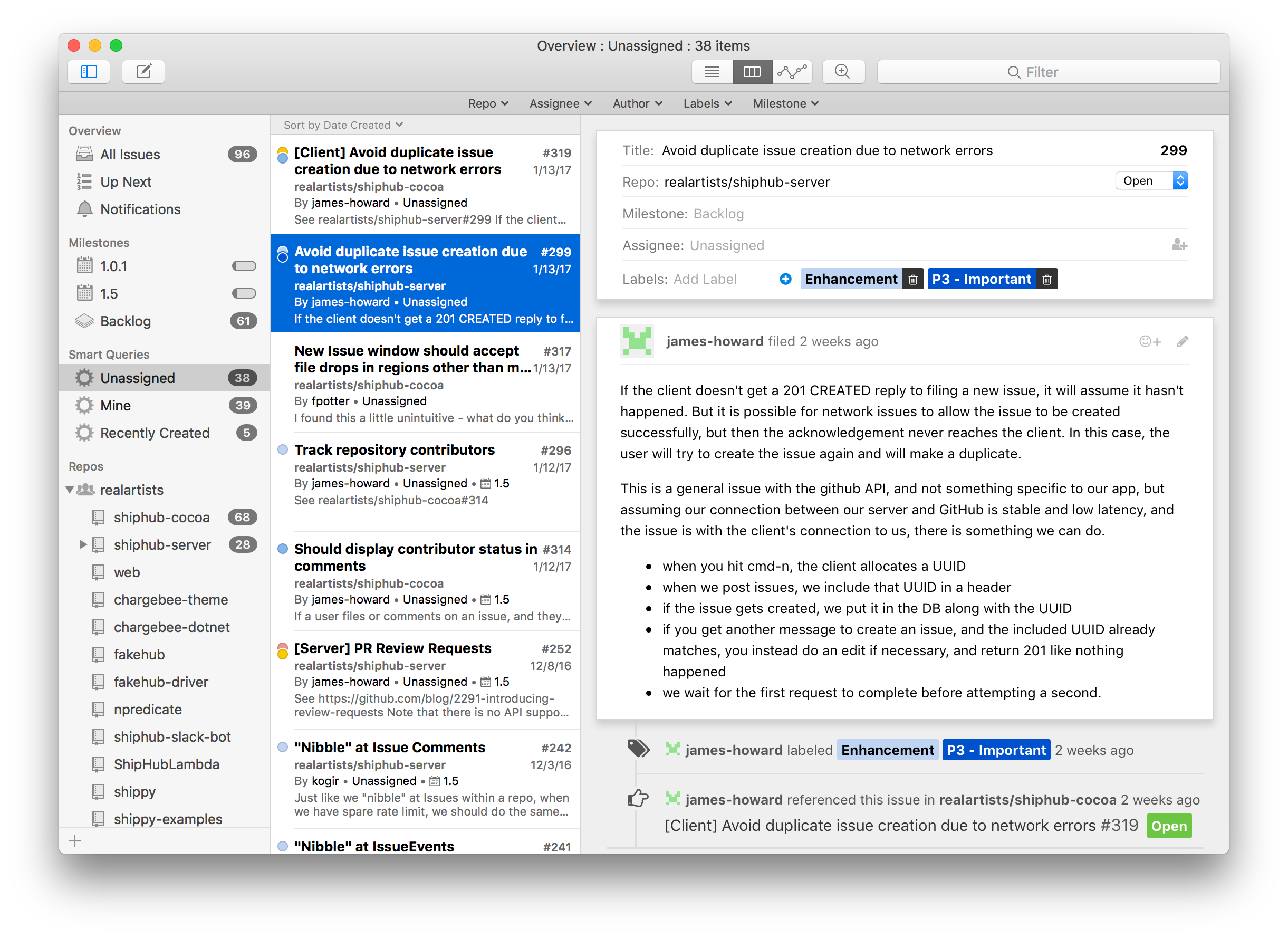
A year ago, when we released Ship 1.0, we knew that GitHub was the most popular place for software projects. This is even more true today. So, when we released Ship 1.0 as a standalone issue tracking service, it was always with the idea in mind that we needed to integrate with GitHub in some fashion. The problem was that we had strong opinions about issue tracking in the areas of performance, rich text and media handling, offline support, query building, workflow and user interface that we wanted the freedom to try to implement in a green field environment.
We are pleased to announce that for Ship 2.0, we've succeeded in bringing many of our best ideas and features from Ship 1.0 to GitHub Issues, along with some new ones we've thought of over the past year. We still offer extremely fast performance backed by a continuously synchronized local database that allows you to query and find issues across all of your GitHub repos instantly. We embraced Markdown and built an excellent editor for composing issues and comments, complete with touch bar support for the new MacBook Pros. Ship 2.0 offers a very complete GitHub Issues experience so that you're never missing any information, and at the same time its feature set is backed completely by GitHub Issues, so collaborators using the web and other platforms aren't missing any information either.
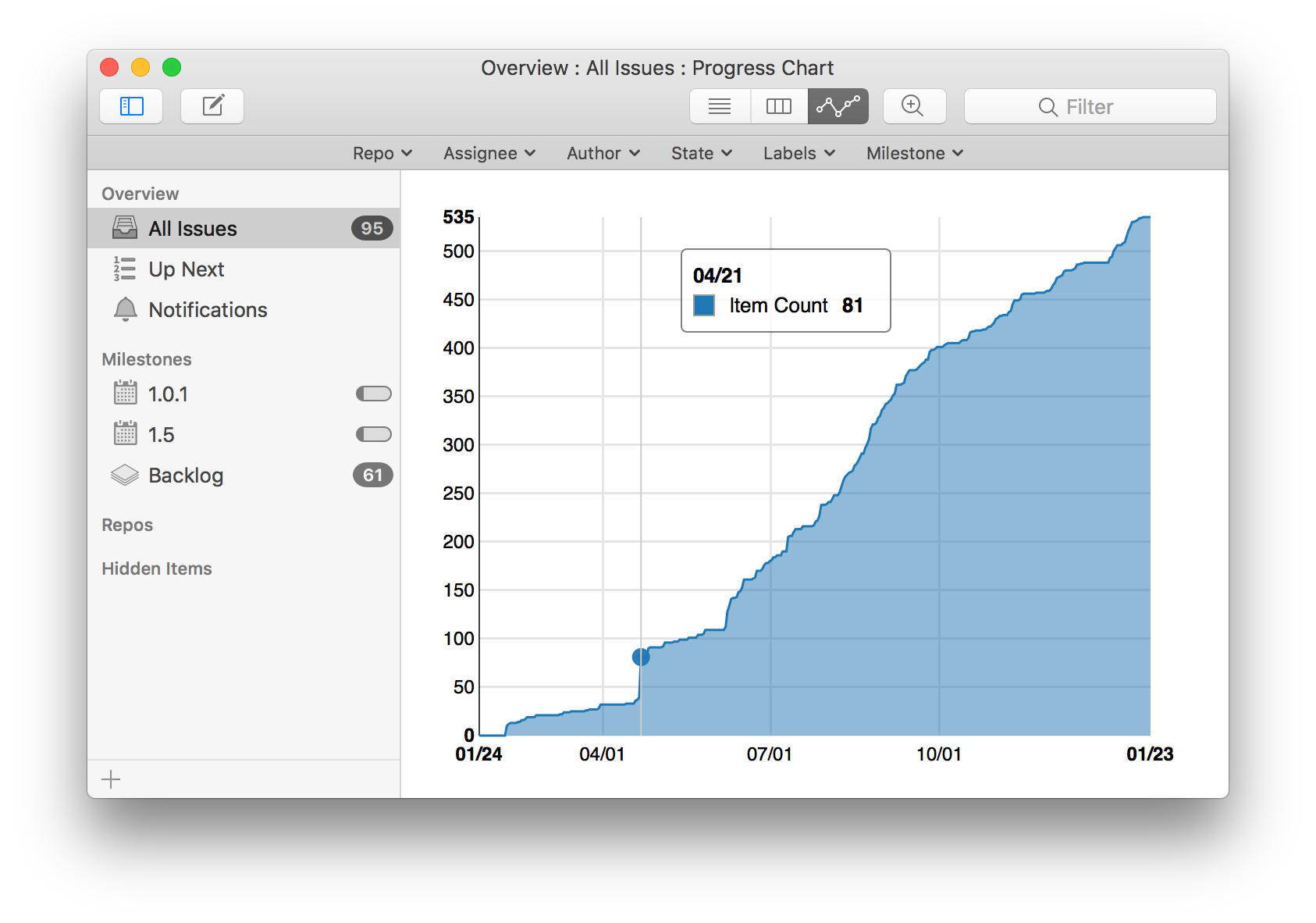
If you use GitHub Issues today, or are thinking about using it in the future, we encourage you to give Ship 2.0 a try. We hope you'll find it easier to stay on top of your issues and to quickly and painlessly file new issues as you find them. We still think using a good native app for issue tracking provides significant productivity advantages, and our own experience bears this out. For example, during development of Ship 2.0, as soon as we got an end to end build working, we found ourselves filing a lot more issues because it became so much more convenient. You can see this in a chart of our total issues (both open and closed) across all of our GitHub repos over the past year:
Technical Notes
It wouldn't be right to end our annual blog post without the traditional section where we highlight some interesting aspects of our system. If you're a nerd like us, this should be fun, if you're not, then, um, maybe skip it.
Ship 2.0 is two parts, a hybrid Cocoa/ObjC/CoreData/JavaScript/React application that runs on your Mac, and a C#/MSSQL/Orleans server that runs in Azure. Oh, and a little bit of glue written in Python running on AWS lambda. Yes, it's truly an unholy alliance.
Why do this? Why not just have a desktop app talking directly to api.github.com and be done with it? We want to minimize the time it takes between when changes are made by others and when you see those changes reflected on your screen. A lot of these changes can be learned about by GitHub API webhooks, but others can only be discovered by polling. We also want to minimize our impact on GitHub's API by sharing data between users as much as possible, while still respecting varying permissions and access rules. Finally, we want to minimize our impact on your Mac's performance and battery life by offloading as much work as we can to Azure, but at the same time recognizing that if we let your Mac do things like query its own issue database locally that we can make many operations feel instant.
Client
The source of truth in the client application is a Core Data database, which in turn is populated from the server via an incremental sync protocol of our own design. It's great to be able to quickly and interactively filter and search your issues across all sorts of attributes, and Core Data and NSPredicate make this easy to express in code and also quite fast to execute. None of this is necessary to know in order to use Ship, as all queries are expressed visually through the user interface, but under the covers that's what's happening: an NSPredicate is built and then executed against a Core Data store.
At the UI layer, issues themselves are presented using web views reflecting the fact that GitHub Issues are fundamentally of the web. GitHub flavored markdown is intended to be rendered as HTML, and can even contain inline HTML directly. A point of pride for us is that many people we have shown Ship 2.0 haven't been able to tell where the web-based content ends and the native Cocoa stuff begins. In fact, the entire "issue" view in the app is web based, both for composing new issues and viewing existing ones:
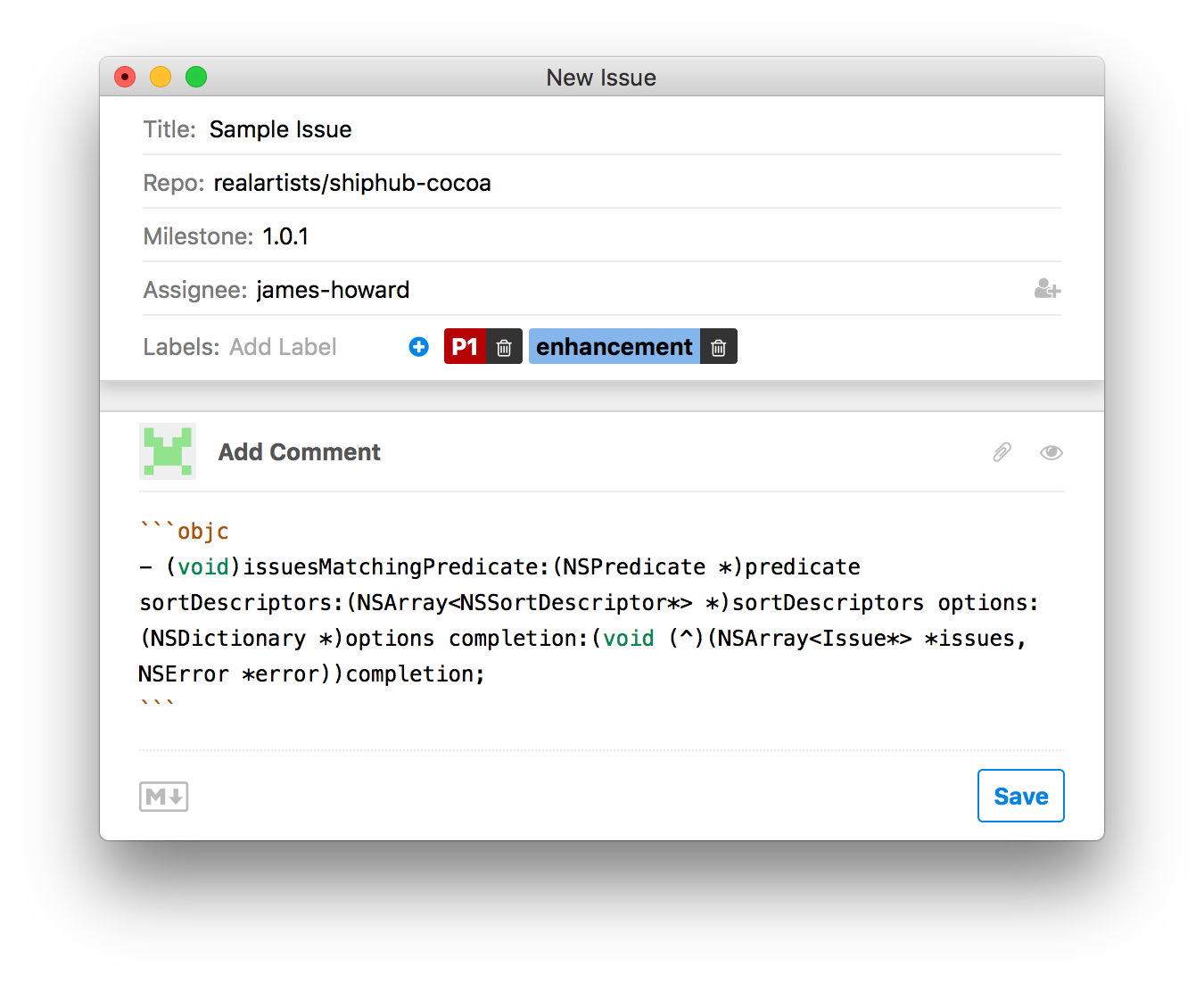
A serialized model of an issue is passed in to the web content as JSON, and then is rendered using React. The nice part of using React here is as live changes to an issue you are viewing come in over the sync protocol, we simply bridge over the updated issue model to the web content and let React update the DOM accordingly.
The markdown editor is a heavily extended CodeMirror, which is a wonderful JavaScript editor. We've added to it integration with the native pasteboard for better copy and paste and drag and drop support (for example, try dragging a folder from the Finder in as an attachment, or put a hidpi image on your clipboard and paste it), native spellchecker support, touch bar support, more macOS native keyboard shortcuts, and GitHub specific features such as username and emoji lookup and completion.
All of the web content in Ship is rendered using the system WebKit. Bridging to JavaScript from native code is convenient with WebKit, and it offers better battery life, memory use, and download size versus bundling yet another Chrome runtime. At the same time, the substantial amount of JavaScript code in Ship can be reused on platforms other than WebKit if we decide to branch out from macOS.
Server
Clients connect to the server via a websocket and present their current sync version. The server then computes and sends changes that have occurred since their last connection (or the full set of data we can know for the user if it's the first connection). In essence, the sync protocol is described completely by the client database schema. The server encodes an entity (think row in a database table, like an account or repository), and then sends it down to the client, which then applies the entity to its database (either set or delete depending on what the server states). Because GitHub data is inherently relational, related entities can either be inlined, linked via identifier, or omitted and related from the other side.
So how does the server compute what to send to the clients? It turns the stream of data it gets from GitHub, either via initial discovery, webhooks, or polling (where absolutely necessary), into a sequential changelog. The server considers all changes since the version reported by the client, then deduplicates and filters the changes respecting the user's permissions. After computing the change set, the server joins it to the latest actual data, and sends it all down in compressed packets to the client. As updates stream in the client applies the changes to its local database. Changes recorded while the client is connected are streamed in near real-time as they occur. This allows the client to be very efficient; it just sits around listening on a (mostly idle) websocket, and it receives pre-massaged data ready to be directly applied to its database, either in bulk or interactively.
One aspect of the server that is particularly novel (and took us three tries to get right) is the GitHub spider. When you log in to Ship for the very first time, we must make a series of requests to the GitHub API to discover information about you, organizations you're in, repositories you have access to, and of course information about your issues. If somebody you work with also uses Ship, we can share the burden of discovering any shared data between you. For example, there's no reason to request the set of valid issue labels for a repository twice just because two different users are interested in it.
So how is this accomplished? We use the Orleans distributed actor framework. Each user, repository, and organization is represented as a "grain" (actor) in Orleans. Each of these grains knows how to learn information about itself, and how to communicate with other grains in the system to detect the latest changes and answer needed questions. For example, as we discover a new repository accessible by a given user, we spin up a grain (or let Orleans find the existing grain) for that repository. We also route all requests to the GitHub API through grains tied to specific users. This allows us to round robin requests for shared information between users where possible and also to throttle our access to GitHub in order to respect API usage limits.
Server Load Testing
One limitation of the GitHub API is that it only really exists as implemented by api.github.com. There is no sandbox environment, creating test users and data on github.com is not allowed, and GitHub Enterprise isn't quite the same as github.com.
As described above, the server architecture is a cooperative one, which means that if we have large numbers of users (or small numbers of users with large amounts of data), we need to ensure that we can support them concurrently. While it would be simpler of course to just to share nothing between users (or let clients talk directly to api.github.com and be done with it), there are significant performance benefits to building our system the way we did. For instance, if you sign up after your teammate has, it's much faster for us to learn about repositories you have access to and then bulk stream issues from our server to your client than it is for us to serially round trip hundreds or thousands of GitHub API requests over HTTP.
To test our server, we decided to build our own API compatible implementation of GitHub. That might sound like a lot of work, but actually it was easy: we built it in just a few days by using Python/Flask/SQLAlchemy. We dubbed it fakehub and loaded it up with a healthy amount of test data.
Now, with the ability to easily simulate thousands of concurrent users, organizations, and repos, and hundreds of thousands of issues, we were ready to see how our server held up. Of course, everything worked perfectly on the first try. Oops. No. We learned a lot about concurrency in SQL Server. Speaking just for myself, I had always kind of thought of client/server relational databases as transparently handling concurrency concerns for you as a user. Sadly, that happy illusion (delusion?) was shattered by this project. Even though the design of our system using Orleans allowed us to largely avoid concurrent updates to the same rows in the database, we had to do a lot of hinting and massaging of query plans in order to get the RDBMS to acquire and release the appropriate locks in the appropriate order.
It would be pure hubris to say that we are ready to handle any load that comes at us, but at least we aren't completely unprepared. If you've read this far, please download Ship 2.0 and we'll see how it goes!